 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Quantum Support Vector Machine algorithm be utilized to identify Key Biomarkers from Multi-Omics data of COVID19 patients?
Apr 29, 2025



Identifying key biomarkers for COVID-19 from high-dimensional multi-omics data is critical for advancing both diagnostic and pathogenesis research. In this study, we evaluated the applicability of the Quantum Support Vector Machine (QSVM) algorithm for biomarker-based classification of COVID-19. Proteomic and metabolomic biomarkers from two independent datasets were ranked by importance using ridge regression and grouped accordingly. The top- and bottom-ranked biomarker sets were then used to train and evaluate both classical SVM (CSVM) and QSVM models, serving as predictive and negative control inputs, respectively. The QSVM was implemented with multiple quantum kernels, including amplitude encoding, angle encoding, the ZZ feature map, and the projected quantum kernel. Across various experimental settings, QSVM consistently achieved classification performance that was comparable to or exceeded that of CSVM, while reflecting the importance rankings by ridge regression. Although the experiments were conducted in numerical simulation, our findings highlight the potential of QSVM as a promising approach for multi-omics data analysis in biomedical research.
Population-Based Evolutionary Gaming for Unsupervised Person Re-identification
Jun 08, 2023Unsupervised person re-identification has achieved great success through the self-improvement of individual neural networks. However, limited by the lack of diversity of discriminant information, a single network has difficulty learning sufficient discrimination ability by itself under unsupervised conditions. To address this limit, we develop a population-based evolutionary gaming (PEG) framework in which a population of diverse neural networks is trained concurrently through selection, reproduction, mutation, and population mutual learning iteratively. Specifically, the selection of networks to preserve is modeled as a cooperative game and solved by the best-response dynamics, then the reproduction and mutation are implemented by cloning and fluctuating hyper-parameters of networks to learn more diversity, and population mutual learning improves the discrimination of networks by knowledge distillation from each other within the population. In addition, we propose a cross-reference scatter (CRS) to approximately evaluate re-ID models without labeled samples and adopt it as the criterion of network selection in PEG. CRS measures a model's performance by indirectly estimating the accuracy of its predicted pseudo-labels according to the cohesion and separation of the feature space. Extensive experiments demonstrate that (1) CRS approximately measures the performance of models without labeled samples; (2) and PEG produces new state-of-the-art accuracy for person re-identification, indicating the great potential of population-based network cooperative training for unsupervised learning.
Deinterlacing Network for Early Interlaced Videos
Nov 27, 2020

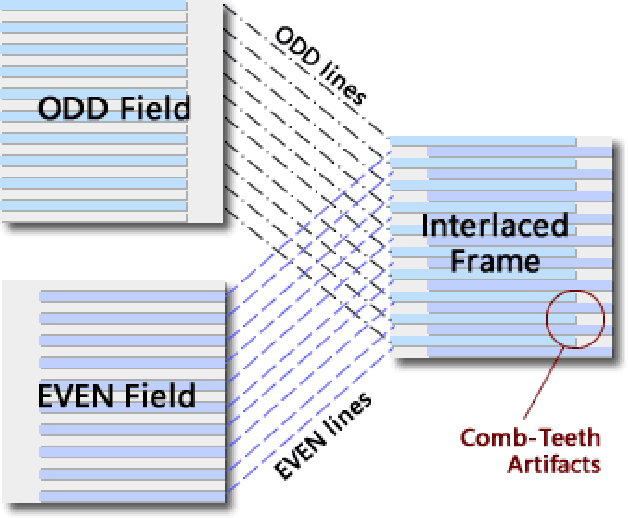
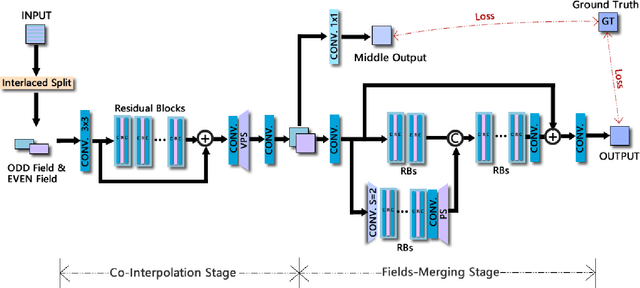
With the rapid development of image restoration techniques, high-definition reconstruction of early videos has achieved impressive results. However, there are few studies about the interlacing artifacts that often appear in early videos and significantly affect visual perception. Traditional deinterlacing approaches are mainly focused on early interlacing scanning systems and thus cannot handle the complex and complicated artifacts in real-world early interlaced videos. Hence, this paper proposes a specific deinterlacing network (DIN), which is motivated by the traditional deinterlacing strategy. The proposed DIN consists of two stages, i.e., a cooperative vertical interpolation stage for split fields, and a merging stage that is applied to perceive movements and remove ghost artifacts. Experimental results demonstrate that the proposed method can effectively remove complex artifacts in early interlaced videos.